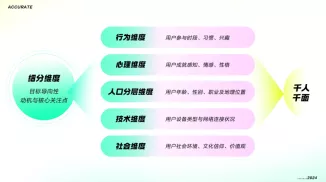
155
|
来源:互联网怪盗团 在中文互联网上,英伟达每天都在被颠覆。绝大部分自媒体和短视频达人都讨厌英伟达,包括周鸿祎在内。他们千方百计地指出,某种替代品(不管是不是国产)的性能指标已经超过英伟达A100或H100,后者即将沦为资本市场历史上最大的泡沫云云。尤其是在B站、小红书这样的平台,“英伟达将迅速被替代”可以被视为一致观点,反对这个观点的人将遭到群嘲。 其实,海外互联网同样如此。昨天还有AI行业的朋友给我分享了一份自称“性能大幅超过英伟达”的美国芯片厂商的自我介绍(是当笑话看的)。几个月前,芯片创业公司Groq发布了自称性能大幅超越英伟达的推理芯片,引发了一定的市场关注度。不同之处在于,海外网友稍微讲一点常识,知道英伟达在训练领域的壁垒实在太高、牢不可破,所以他们主要从推理环节入手:可以针对大模型推理开发某种高度特化的“推理专用卡”,在性能或性价比上超越英伟达,而且已经有人做到了。这些观点经常被翻译为中文,不过翻译者经常有意地把其中的海外芯片创业公司的名字偷换成A股上市公司(或某家非上市公司),从而达到不可告人的目的。 遗憾的是,至少在现在,以及可见的未来,英伟达在推理方面的壁垒仍然十分牢固。或许它在推理方面的壁垒不如训练方面那么高,但只要竞争对手攻不破,就没什么区别。对于绝大部分大模型开发商以及云计算厂商而言,AI算力建设只能以英伟达为核心(买不到的情况除外),不论是训练还是推理算力。在展开分析这个问题前,让我们先简明回顾一下训练和推理的区别:
AMD和英特尔的“AI加速卡”(其实就是推理卡)卖得都不怎么样。其中,AMD的旗舰产品Instinct MI300的单季度销售额不足10亿美元,2024年全年的目标也仅仅是卖出40亿美元;英特尔的旗舰产品Gaudi 3就更惨了,2024年全年的销售目标不足10亿美元。把这两家的AI硬件销售额加起来,恐怕都只有英伟达“中卡”销量的一个零头。在2024年一季度财报发布会上,苏妈承认AMD的推理卡目前不存在供给瓶颈,客户可以随时提货;隔壁的英伟达几乎所有产品线则都处于紧缺状态。换句话说,大部分客户宁可等上一两个季度,也宁可买英伟达而不是AMD的产品。 与此同时,在硅谷出现了一个新的趋势:尽可能多地采购“大卡”,把推理和训练一起交给“大卡”去做。例如,OpenAI将使用较新的H200承担GPT-4o的推理任务;苹果通过鸿海采购了数万张H100,估计主要将用于推理工作;Meta计划在2024年之内新增35万张H100,其中很大一部分将用于推理;亚马逊采购的首批3万多张GB200“超级芯片”显然将同时用于训练和推理。这充分说明,所谓“英伟达在推理方面的护城河不深”的说法是何等荒谬!如果上述说法是真的,那么除非大厂钱多烧得慌,否则完全没有必要采购单价极高、供应非常紧张的英伟达“大卡”承担推理任务。当然,这些大厂也会采购一点点AMD或英特尔的产品作为补充,每次都会引发后两者的欢呼雀跃,恨不得让全世界都知道。 为什么硅谷大厂要花更多的钱去采购专为训练优化的“大卡”承担推理任务?这既是出于技术考虑,也是出于综合成本考虑。简而言之:
 现在假设有一种推理卡,不知道为什么竟能实现远高于英伟达的性能(可能是上帝显灵),而且竟能克服缺乏CUDA生态的麻烦(这次上帝得多受累一点),并且纸面价格显著低于英伟达(这一点极难做到),它也不一定能打败英伟达。客户首先要考虑通用性:专门为大语言模型推理“特化”的芯片,大概率无法拿来执行任何其他任务,从而带来了更高的机会成本。英伟达是“通用计算GPU”概念的提出者,“通用”概念就意味着灵活性和弹性。远的不说,最近几年我们就能看到许多鲜活的案例: 2021-2022年,为了进一步训练内容推荐算法,以符合欧盟消费者隐私要求,以及支持新推出的Reels短视频功能,Meta(原名Facebook)采购了大量英伟达“大卡”;当然其中一部分也是为“元宇宙”研发准备的。Meta还成为了2022年发布的H100显卡早期最重要的客户之一。ChatGPT横空出世之后,Meta立即将手头的算力资源投入生成式AI研发,迅速成为全球开源大模型领域的第一平台。扎克伯格本人亦承认,生成式AI浪潮来的时机很巧,Meta非常幸运——其实他更应该感谢英伟达显卡的通用性和普适性。 2019年前后,中国的“云游戏”产业处于井喷阶段,资本市场对其有很高预期。包括阿里、腾讯和电信运营商在内的云计算大厂纷纷采购了大批英伟达RTX显卡(初期主要是Turing架构,后来亦有Ampere架构)组建刀片服务器。虽然云游戏在国内没火起来,但是高端RTX显卡具备张量核心(Tensor Core),从而拥有一定的推理能力。在美国芯片法案的阴影之下,国内厂商采购推理卡越来越困难,当年积累的“云游戏卡”扮演了雪中送炭的角色;尽管它们的推理效率肯定比不上L40等“中卡”,但有总比没有好。 (附带说一句,为什么英伟达的消费级显卡也装备了Tensor Core? 因为它对于光线追踪技术的实现扮演着不可或缺的角色,而光线追踪能够大幅提升游戏画面的感染力。显卡处理游戏内部光影效果的方式,与处理大模型数据的方式,在硬件和数学层面是互通的。人类如果没有强大的游戏产业,就很难建设强大的人工智能产业。) 我们不知道生成式AI产业的下一步走向是什么:Transformer架构(现在所有大语言模型的基础)诞生至今才七年多,第一个百亿参数的大模型诞生至今才不到五年。就像许多学者指出的一样,生成式AI有可能并不是实现通用人工智能(AGI)的必由之路。但是无论如何,有一点是确定的:未来的世界需要大量算力,尤其是并行的、以多核GPU为基础的算力。当生成式AI浪潮突然降临之时,许多科技大厂都把自家的英伟达显卡从自动驾驶、推荐算法训练、图形渲染等任务迅速转移到了大模型相关任务;这进一步加深了它们对英伟达的信任和依赖。 此时此刻,全球科技巨头用于扩张算力的资本开支,普遍达到了每年几百亿美元的水平;坊间甚至传闻微软打算在一年之内耗资1000亿美元建设新的数据中心。花了这么多的钱,它们肯定不希望自己买到的算力仅能用于非常狭窄的领域,不管其纸面性能好坏、价格高低。所以那些高度特化的推理卡,注定只能在巨头的算力军备竞赛当中扮演次要角色;AMD能扮演的角色可以更重要一点,但离英伟达这个主角还是差得很远。 就在本文撰写的过程中,我的另一位从事AI行业多年的朋友告诉我:“我们最近开始采购另一家公司的显示芯片了。它的硬件规格是合格的,但是软件适配是大问题,需要踩很多的坑。英伟达的CUDA开发团队应该比硬件设计团队的规模要大得多,它的发布会上几乎全是软件生态工具,例如GPU虚拟化、一键部署。缺少了英伟达的软件生态,我们就要自己雇人去实现这些能力。生态就是成本!没有生态就要产生额外的开发成本。”当然,鉴于国内现在越来越难买到英伟达的数据中心级显卡,厂商只能硬着头皮承担成本;在有选择的情况下,它们几乎不会有动力这样做。 至于五年、十年乃至二十年后呢?那就是另一个问题了。通用计算GPU这个概念诞生至今也只有十八年,NVLink技术也只有十年历史。在长期,一切都是可以改变的,但是一切改变只能来自勤奋耕耘和咬定青山不放松的精神。请记住,2013年,当黄仁勋操着半生不熟的普通话在北京国家会议中心的舞台上说“请给我一个机会介绍英伟达”的时候,他已经到处推销自己的通用计算理念长达七年了;而他还要再等待整整九年,才能看到一切开花结果。当时嘲笑他的人,和现在认为可以轻易替代他的人,很可能是同一批人。 文章来源:“互联网怪盗团”,未经允许不得转载。 文章代表作者观点,版权归原作者所有,热传平台仅提供信息存储空间服务。 |

|

|

|

|

|
2024-11-05
2024-09-29
2024-09-26
2024-09-26
2024-09-24
2024-09-24
2024-09-24
2024-09-24
版权归原作者所有,如有任何问题,联系更正删除。| QQ/WX:771661581 | 请加微信联系 | 我要投稿
热传网 | 鄂ICP备2021016389号 | 网备 46902302000123号 | ©2021 ReChuan NET. Powered by ReChuan
网备 46902302000123号 | ©2021 ReChuan NET. Powered by ReChuan


 产品观察
产品观察